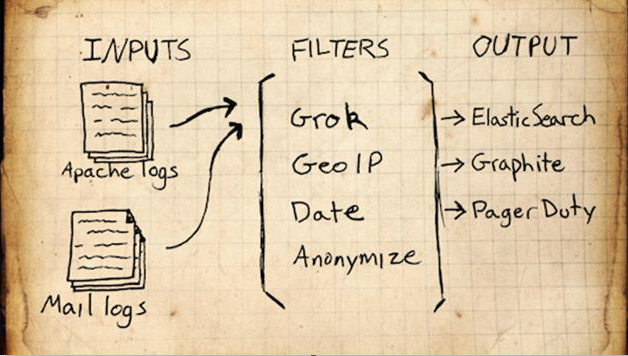
ELK简介:
ELK 是 由 Elasticsearch 、 Logstash 、 Kibana 、 filebeat 三个开源软件组成的一个组合体,这三个软件,每个软件用于完成不同的功能, ELK 又称为 ELK stack。官方域名为 elastic .co
ELK有以下优点:
- 处理方式灵活: elasticsearch 是实时全文索引,具有强大的搜索功能。
- 配置相对简单: elasticsearch 全部使用 JSON 接口,logstash 使用模块配置,kibana 的配置文件部分更简单。
- 检索性能高效: 基于优秀的设计 ,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级 响应。
- 集群线性扩展: elastic search 和 logstash 都可以灵活线性扩展。
- 前端操作绚丽: kibana 的前端设计比较绚丽 ,而且操作简单。
Elasticsearch简介:
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比如 Nginx 、 Tomcat 、系统日志等功能 。
Logstash简介:
可以通过插件实现日志收集 和 转发 ,支持日志过滤,支持普通 log 、自定义 json 格式的日志解析 。
kibana简介:
通过接口调用 elasticsearch 的数据,并进行前端数据可视化的展现。
ELK的方便之处:
ELK组件在海量日志系统的运维环境中,起到了如下功能:
- 分布式日志数据统一收集 ,实现 集中式查询和管理
- 故障排查
- 安全信息和事件管理
- 报表功能
ELK组件在大数据运维系统中,主要可解决的问题如下:
- 日志查询,问题排查,故障恢复,故障自愈
- 应用日志分析 ,错误报警
- 性能分析,用户行为分析
使用场景:
elasticsearch部署:
单节点elasticsearch带安全节点间访问参看链接:
https://blogs.jinchenghe.top/?p=559
环境初始化,本次使用主机Ubuntu1804.01系统
- 修改主机名和磁盘挂载
- 关闭防火墙和selinux
- 各服务器配置本地域名解析,如果内部有DNS服务器更佳
- 设置 aliyun epel 源 、 安装基本操作命令,并同步时间
- 在 host1 和 host2 分别安装 elasticsearch,需要提前配置JAVA环境,需辨析二进制、apt-get、yum安装的java,配置环境变量时,JAVA_HOME目录的不同。
官网下载 elasticsearch 或者 清华大学仓库下载 并安装:
https://www.elastic.co/cn/downloads/elasticsearch
两台服务器分别安装 elasticsearch:
主节点服务器:
root@elasticsearch ~]#dpkg -i elasticsearch-6.8.1.deb
root@elasticsearch ~]#grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elasticsearch-cluster #集群名称
node.name: node-1 #节点名称
path.data: /data/elasticsearch #自定义存储目录
path.logs: /data/elasticsearch.log #自定义log存储目录
bootstrap.memory_lock: true #锁定内存,直接申请jvm.options中定义内存,并锁定,需配合/limits.conf中相关参数。
network.host: 192.168.7.10 #服务器地址
http.port: 9200 #监听端口
#集群单点广播,适用于公有云,本地主机
discovery.zen.ping.unicast.hosts: ["192.168.7.10", "192.168.7.11"]
#开启跨域访问支持,此两项为了后面head监控软件做铺垫,若不适用,则可不配置
http.cors.enabled: true
http.cors.allow-origin: "*"
从节点服务器:
root@elasticsearch2 ~]#grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elasticsearch-cluster
node.name: node-2
path.data: /data/elasticsearch
path.logs: /data/elasticsearch.log
bootstrap.memory_lock: true
network.host: 192.168.7.11
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.7.10", "192.168.7.11"]
http.cors.enabled: true
http.cors.allow-origin: "*"
分别在两台服务器创建 data 目录,并修改属主属组:
此目录最好存储在单独分区或单独硬盘分区上。
# mkdir /data
# chown -R elasticsearch.elasticsearch /data
修改内存限制,并同步配置文件:
内存锁定的配置参数,参看官方文档:
https://discuss.elastic.co/t/memory-lock-not-working/70576
root@elasticsearch ~]#vim /usr/lib/systemd/system/elasticsearch.service
36 LimitMEMLOCK=infinity #无限制使用内存,此为添加项
#修改最大最小内存,本次实验为1g内存,因本物理机内存只有8G
root@elasticsearch ~]#vim /etc/elasticsearch/jvm.options
22 -Xms2g
23 -Xmx2g
为何修改最大最小内存相同,官方配置文档最大建议内存 30 G 以内 。参看官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
启动elas服务,查看监听端口和日志:
监听端口:9200端口用来查看服务状态,9300端口用来传输数据。
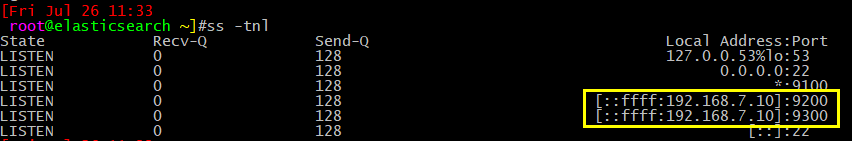
只启动node-1服务器时:
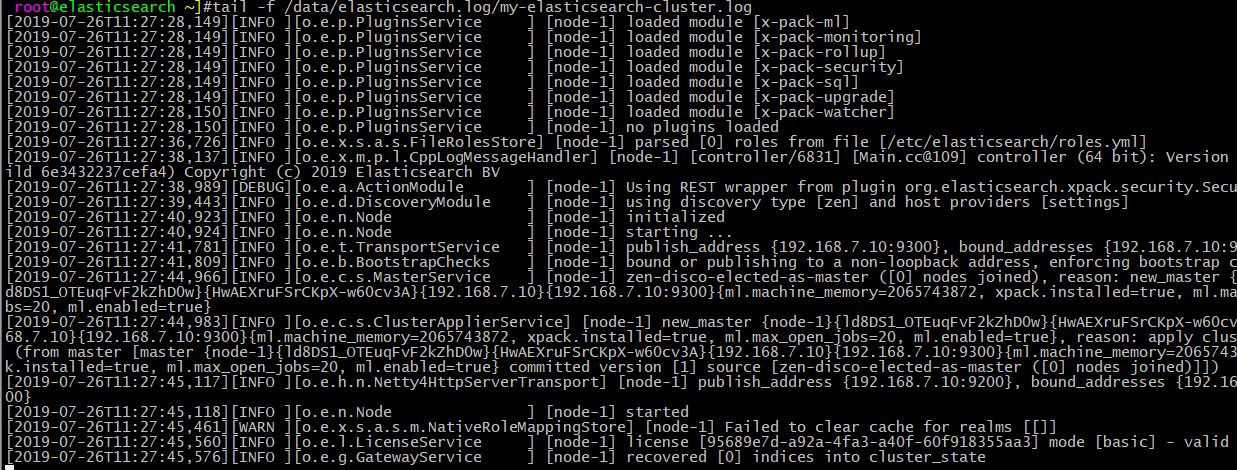
继续启动node-2服务器:

通过浏览器访问 elasticsearch 服务端口:
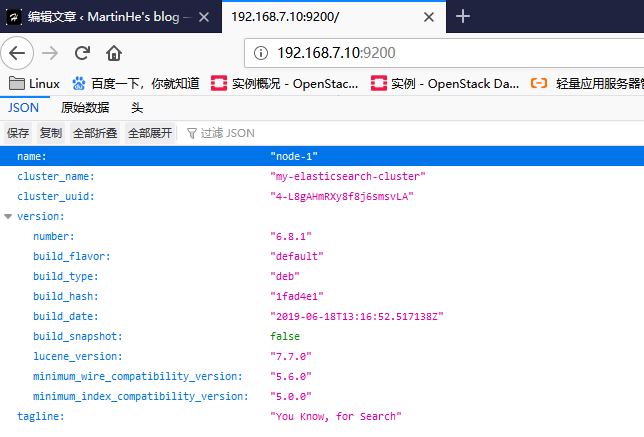
安装 elasticsearch 插件 之 head
Master 与 Slave 的区别:
- Master的职责:统计各 node 节点状态信息、集群状态信息统计 、索引的创建和删除、 索引分配的管理、关闭 node 节点等
- Slave的职责:从 master 同步 数据、等待机会成为Master
爱好者提供的插件,可以实现对 elasticsearch 集群的状态监控与管理配置等功能。
安装 5.x 版本 的 head 插件:
需要通过启动一个服务方式, git 地址:
https://github.com/mobz/elasticsearch-head
本次实验使用docker,容器的方式启用head
root@elasticsearch ~]#docker load < /opt/elasticsearch head docker.tar.gz
root@elasticsearch ~]#docker run -d -p 9100:9100 --name elastic docker.io/mobz/elasticsearch-head:5

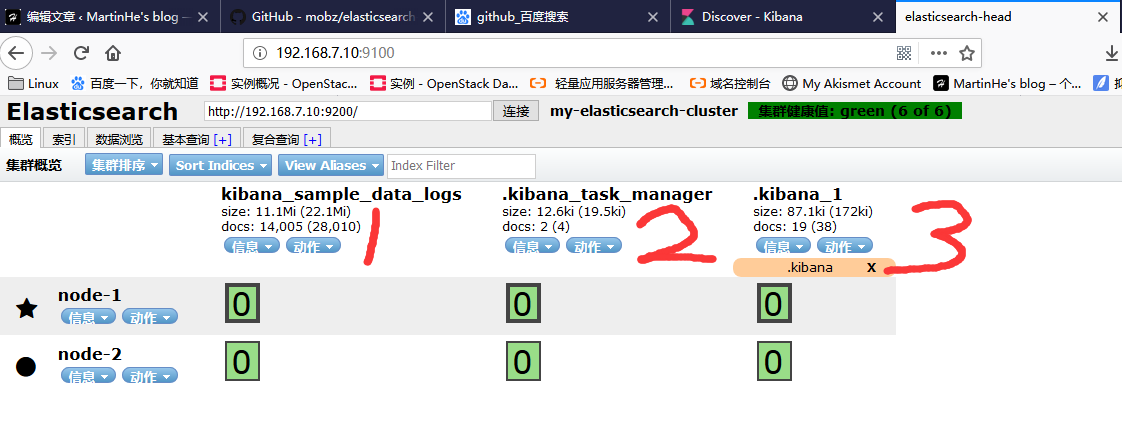
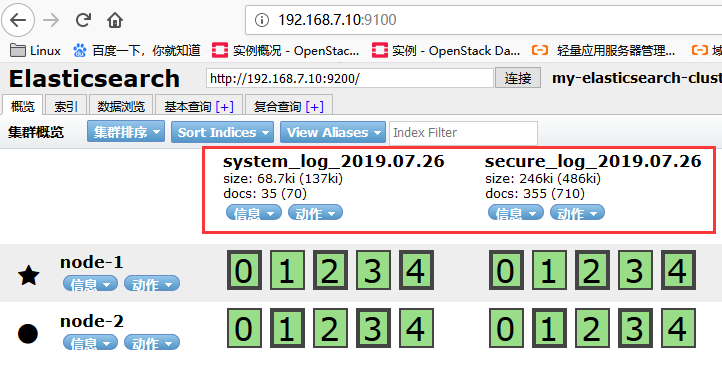
浏览器打开:http://192.168.7.10:9100 , 主从节点的选择,谁先启动,谁就是主节点,星星为主节点,圆点为从节点
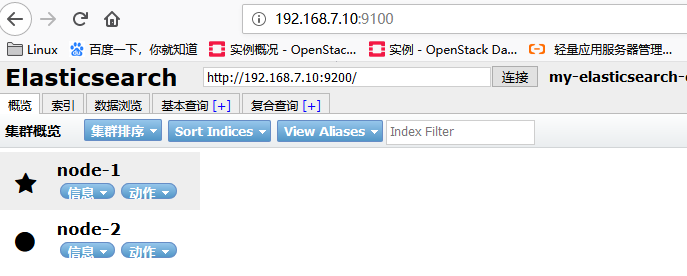
注意:如果宿主机内存不足,系统内核会将占用内存 最大的进程强制 kill 掉,以保证系统的正常运行,以及其他服务的正常运行。
监控 elasticsearch 集群状态
通过 shell 命令获取集群状态
#curl -sXGET http://192.168.7.10:9200/_cluster/health?pretty=true
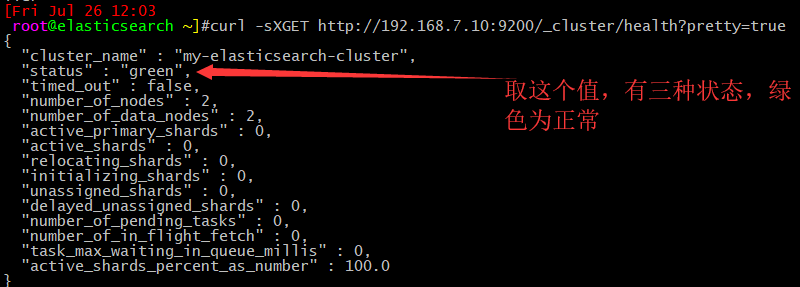
如果等于 green( 绿色 ) 就是运行在正常,等于yellow( 黄色 )表示副本分片丢失, red( 红色 )表示主分片丢失。
python 脚本:
#!/usr/bin/env python
#coding:utf-8
#Author Zhang Jie
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
import subprocess
body = ""
false="false"
obj = subprocess.Popen(("curl -sXGET http://192.168.7.10:9200/_cluster/health?pretty=true"),shell=True,stdout=subprocess.PIPE)
data = obj.stdout.read()
data1 = eval(data)
status = data1.get("status")
if status == "green":
print("50")
else
print("100")
zabbix 添加 监控
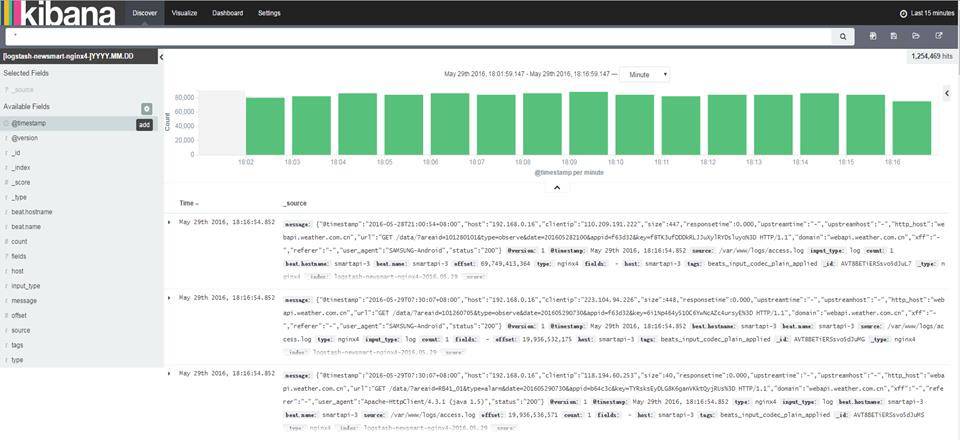
kibana部署及日志收集:
Kibana是一个通过调用 elasticsearch 服务器进行图形化展示搜索结果的开源项目。
安装并配置 kibana
可以通过 rpm 包或者二进制的方式进行安装。
root@elasticsearch ~]#dpkg -i kibana-6.8.1-amd64.deb
root@elasticsearch ~]#grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: 5601
server.host: "192.168.7.10"
server.name: "my-kibana"
elasticsearch.hosts: ["http://192.168.7.10:9200"]
i18n.locale: "zh-CN"
root@elasticsearch ~]#dpkg -i kibana-6.8.1-amd64.deb
root@elasticsearch ~]#systemctl start kibana.service
root@elasticsearch ~]#systemctl enable kibana.service
访问kibana地址:
http://192.168.7.10:5601
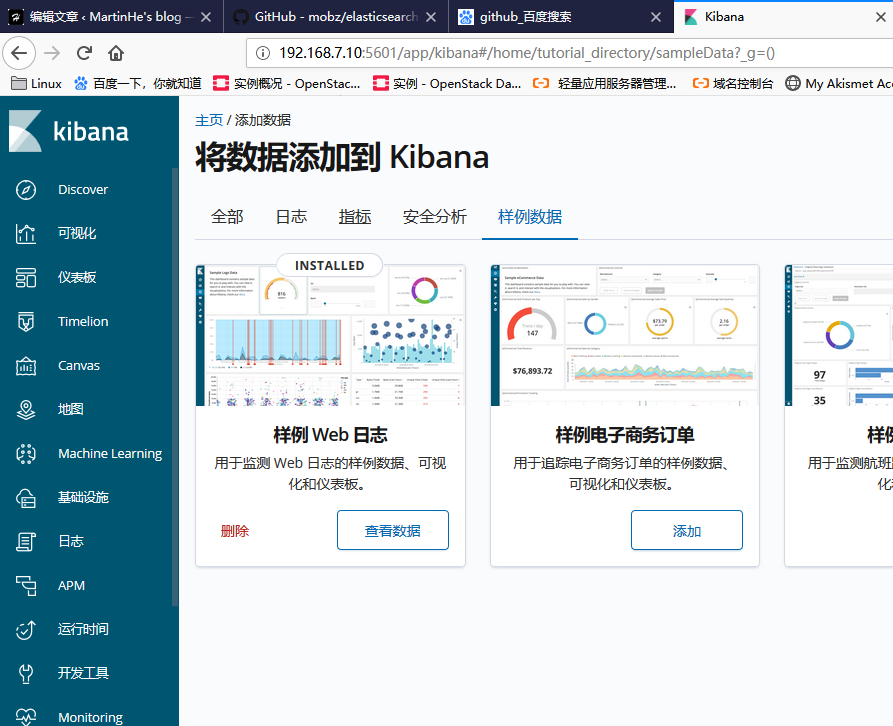
kibana中的索引存放位置:
注意:不要进入数据目录删除数据。
root@elasticsearch ~]#ll /data/elasticsearch/nodes/0/indices/
total 20
drwxr-xr-x 4 elasticsearch elasticsearch 4096 Jul 26 12:45 jH0GoOQtT3CPMvuMQO39_w/
drwxr-xr-x 4 elasticsearch elasticsearch 4096 Jul 26 12:48 JyTaUzeZRSS1FYGmlo_-3A/
drwxr-xr-x 4 elasticsearch elasticsearch 4096 Jul 26 12:45 uvz1QnfIQ-W_G6thbYkAnw/
[Fri Jul 26 13:25
查看状态:
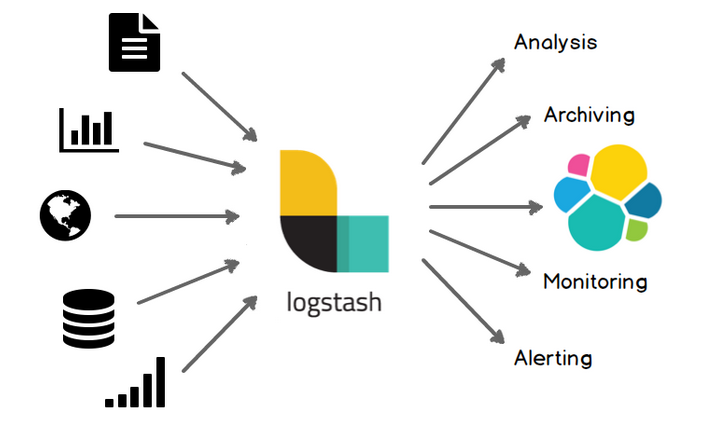
部署logstash:
官方文档:
https://www.elastic.co/guide/en/logstash/6.8/introduction.html
Logstash 是一个开源的数据收集引擎, 可以水平伸缩, 而且 logstash 整个 ELK 当中拥有最多插件的一个组件, 其可以 接收 来自不同 来源 的数据,并统一 输出 到指定的,且可以是多个不同目的地。
提前部署Java环境
本实验安装的全部是openjdk-8-jdk
# apt-get install openjdk-8-jdk
# vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
# source /etc/profile.d/java.sh
开始安装logstash:
https://www.elastic.co/guide/en/logstash/6.8/installing-logstash.html
Logstash requires Java 8 or Java 11. Use the official Oracle distribution or an open-source distribution such as OpenJDK.
root@logstash ~]#dpkg -i logstash-6.8.1.deb
logstack环境初次检测:
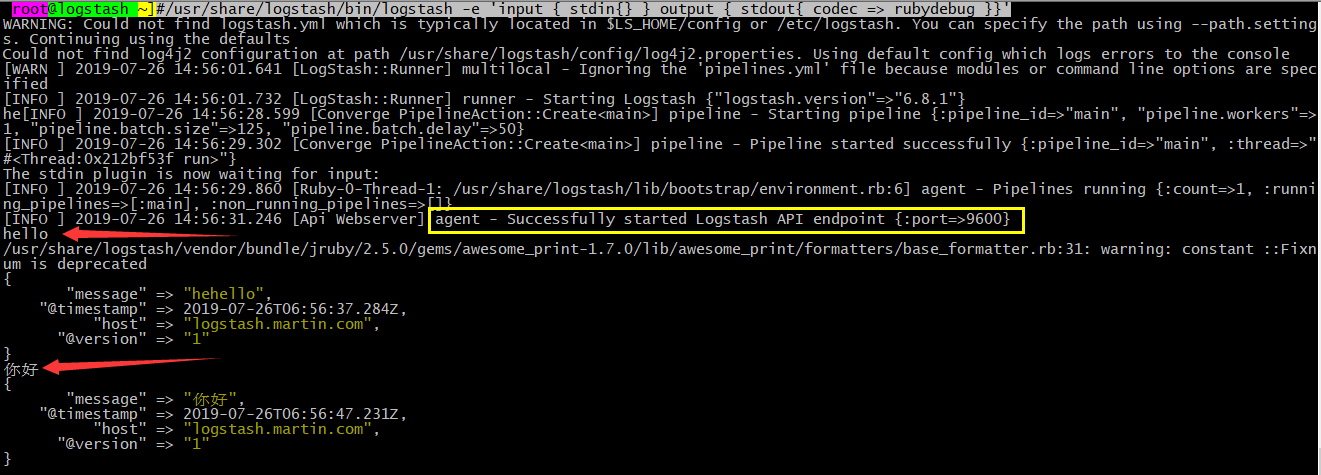
root@logstash ~]#/usr/share/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug }}'
你好
{
"message" => "你好", #消息
"@timestamp" => 2019-07-26T06:56:47.231Z, #时间戳,非本地时间,差8h
"host" => "logstash.martin.com", #发生在哪台主机
"@version" => "1"
}
测试往本地文件内写入数据信息:
root@logstash ~]#/usr/share/logstash/bin/logstash -e 'input { stdin{} } output { file { path => "/tmp/logstash-%{+Y-MM-dd}.log"}}'
hello
你好
Welcome To logstash
#查看输出的文件内容:
root@logstash ~]#cat /tmp/logstash-2019-07-26.log
{"@version":"1","host":"logstash.martin.com","@timestamp":"2019-07-26T07:17:02.805Z","message":"hello"}
{"@version":"1","host":"logstash.martin.com","@timestamp":"2019-07-26T07:17:12.611Z","message":"你好"}
{"@version":"1","host":"logstash.martin.com","@timestamp":"2019-07-26T07:17:28.702Z","message":"Welcome To logstash"}

测试输出到 elasticsearch
特别注意:一定要安装官方给出的写法:后面这种写法不支持:“http://192.168.7.10:9200”
/usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.7.10:9200"] index => "my-test-log-%{+YYYY.MM.dd}"}}'
hello
你好
Welcome To Logstash
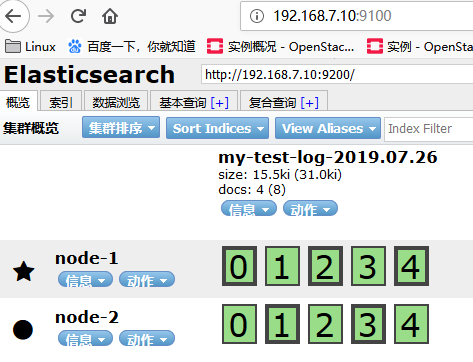
通过elaticsearch-head Web界面查看,方框的虚实框,粗框表示数据在此节点,细框表示备份数据在此节点。
在kibana中添加索引字段
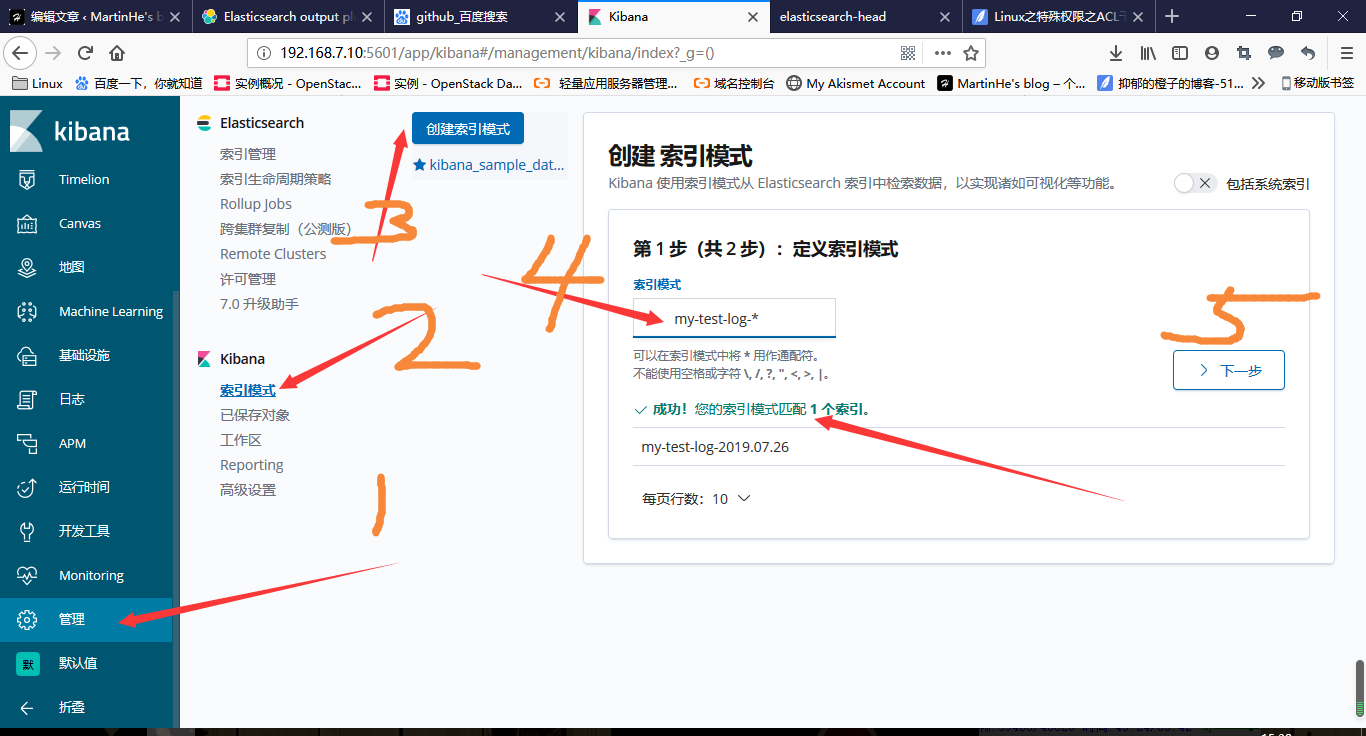
**选择Discover,查看my-testlog1-***
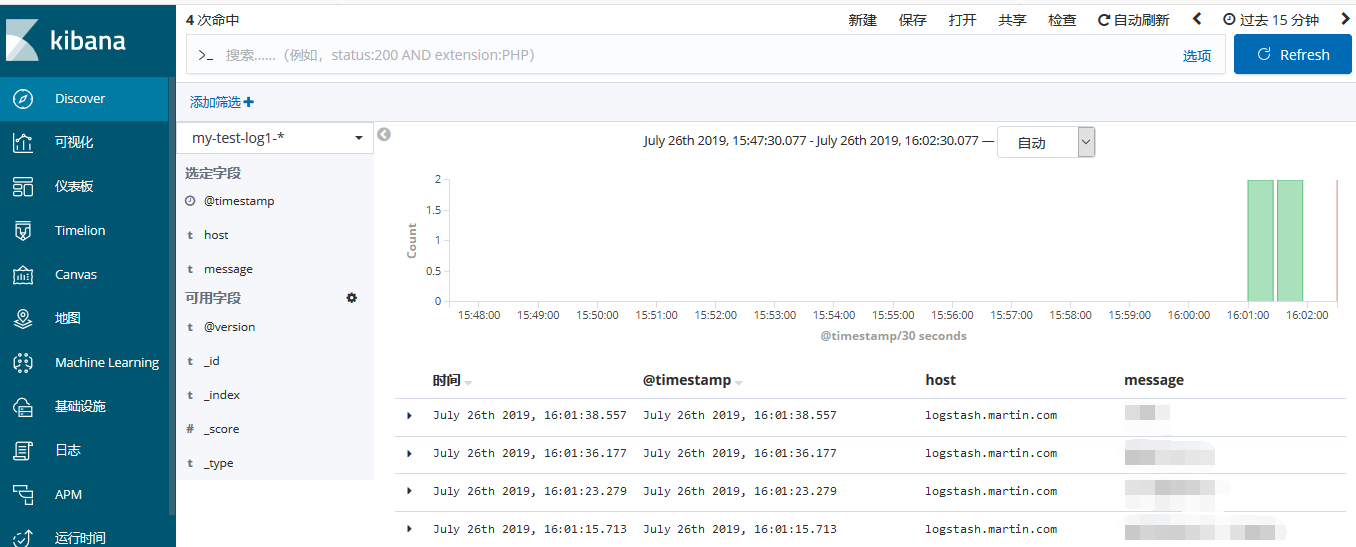
通过logstash收集日志:
收集单个系统日志并输出至文件
前提需要 logstash 用户对被收集的日志文件有读的权限,并对写入的文件有写权限。
自定义 logstash 配置文件:
root@logstash ~]#vim /etc/logstash/conf.d/syslog.conf
input {
file {
type => "messagelog"
path => "/var/log/syslog"
start_position => "beginning" #or end
}
}
output {
file {
path => "/tmp/syslog-%{+Y-MM-dd}.log"
}
}
检测配置文件语法是否正确:

启动logstash服务,并查看相关日志,报错如下:
注意:logstash使用自身用户启动,对/var/log/syslog没有读取权限,此时就需要额外设置ACL权限

root@logstash ~]#setfacl -m u:logstash:r /var/log/syslog
#getfacl /var/log/syslog
getfacl: Removing leading '/' from absolute path names
# file: var/log/syslog
# owner: syslog
# group: adm
user::rw-
user:logstash:r--
group::r--
mask::r--
other::---
#查看logstash输出的文件:
#ll /tmp/syslog-2019-07-26.log
-rw-r--r-- 1 logstash logstash 4561093 Jul 26 16:43 /tmp/syslog-2019-07-26.log
查看logstash输出的文件:

通过logstash收集多个日志文件:
root@logstash ~]#setfacl -m u:logstash:r /var/log/syslog
自定义 logstash 配置文件:
root@logstash ~]#vim /etc/logstash/conf.d/sys_secure.conf
input {
file {
type => "systemlog" #此type类型必须与下面判断一致,佛则被丢弃
path => "/var/log/syslog"
start_position => "beginning" #or end
stat_interval => "3" #日志收集时间间隔
}
file {
type => "securelog"
path => "/var/log/auth.log"
start_position => "beginning" #or end
stat_interval => "3" #日志收集时间间隔
}
}
output {
if [type] == "systemlog" {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "system_log_%{+YYYY.MM.dd}"
}
}
if [type] == "securelog" {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "secure_log_%{+YYYY.MM.dd}"
}
}
}
重启logstack服务使配置文件生效:
# systemctl restart logstash
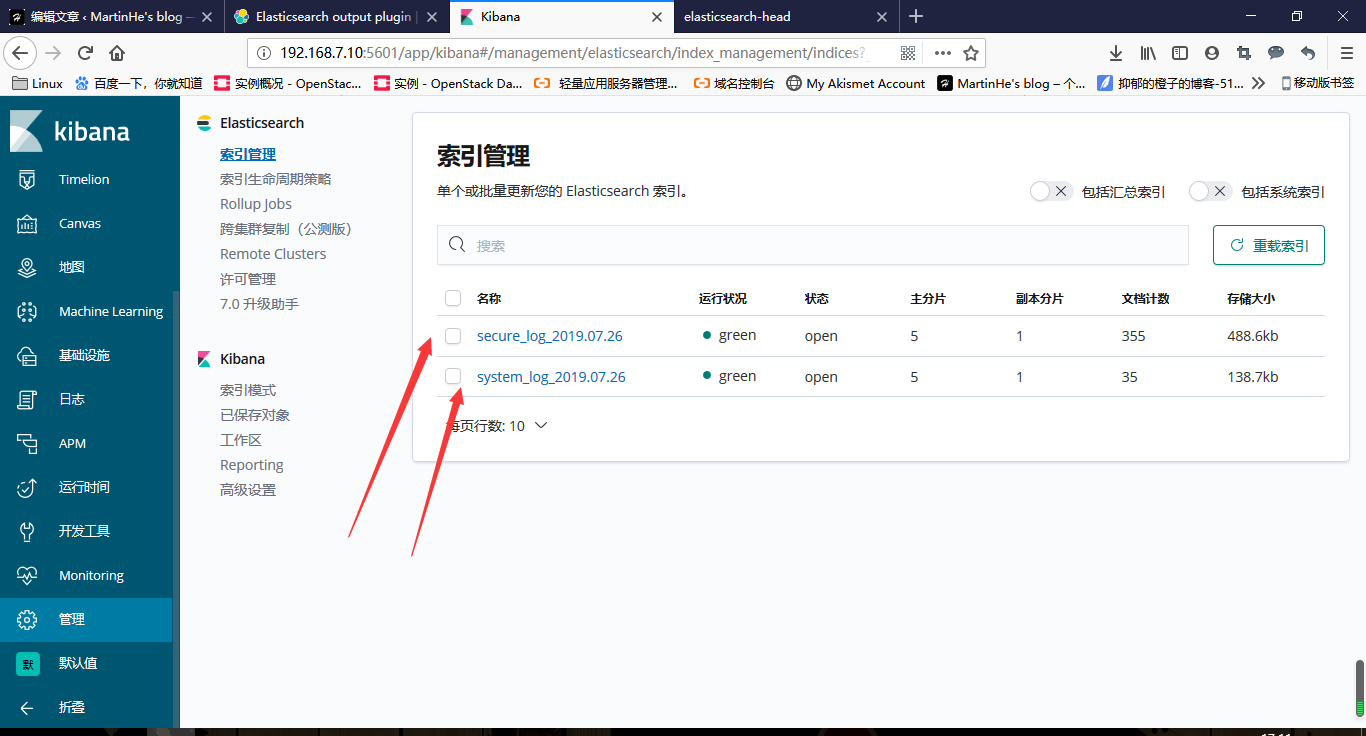
查看els-head Web界面
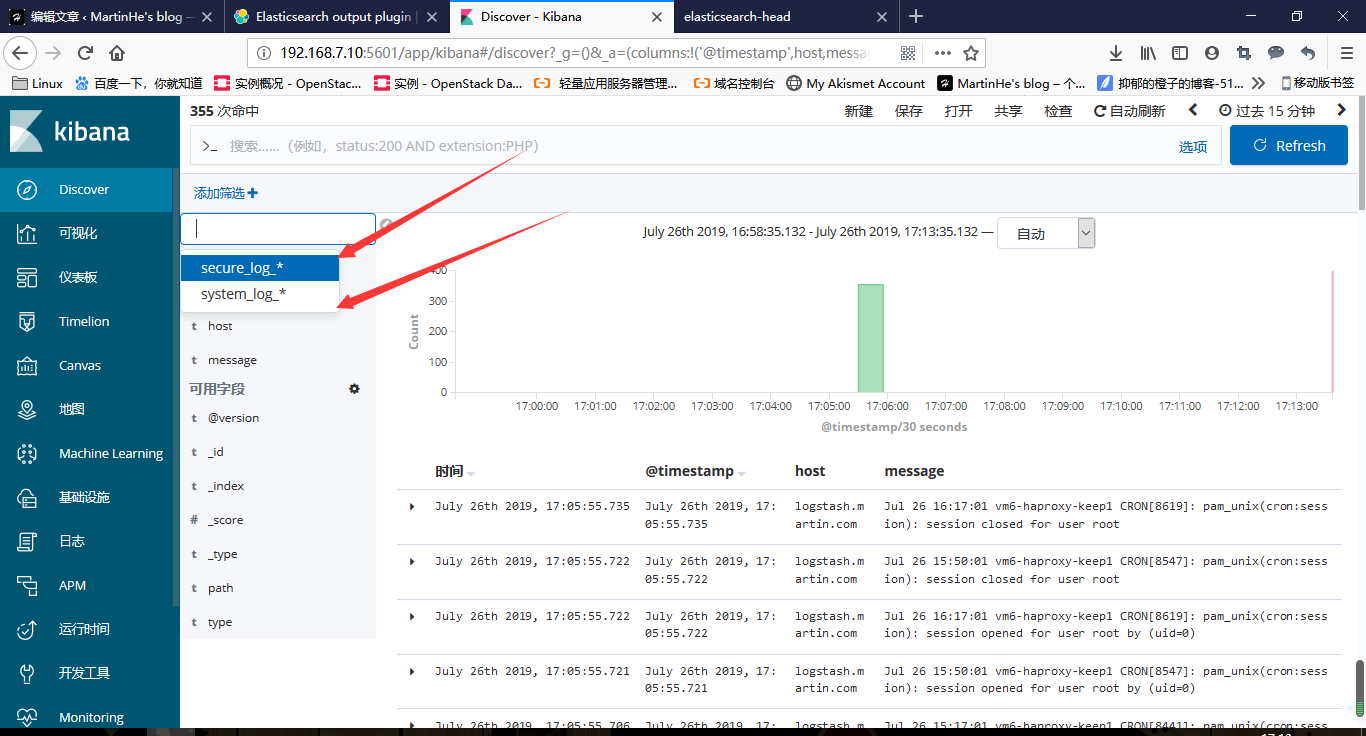
查看kibana界面
添加索引项后
通过 logtsash 收集 tomcat 和 java(logstash-plain.log) 日志
收集 Tomcat 服务器的访问日志以及 Tomcat 错误日志进行实时统计,在 kibana 页面进行搜索展现,每台 Tomcat 服务器要安装 logstash 负责收集日志,然后将日志转发给 elasticsearch 进行分析,在通过 kibana 在前端展现,配置过程如下:
服务器部署 tomcat 服务(logstash服务器上安装):
配置tomcat日志格式为json格式:
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="tomcat_access_log" suffix=".log"
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","method":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","AgentVersion":"%{User Agent}i"}"/>
</Host>
apache日志格式详解:
https://www.cnblogs.com/wajika/p/6605939.html
重启tomcat服务验证日志格式
拷贝到网站验证是否为正确的Json格式日志
#./usr/local/tomcat/bin/shutdown.sh
#./usr/local/tomcat/bin/startup.sh
#tail -f /usr/local/tomcat/logs/localhost_access_log.2019-07-26.txt
{"clientip":"192.168.0.1","ClientUser":"-","authenticated":"-","AccessTime":"[26/Jul/2019:18:11:47 +0800]","method":"GET /favicon.ico HTTP/1.1","status":"200","SendBytes":"21630","Query?string":"","partner":"-","AgentVersion":"-"}
自定义 logstash 配置文件:
一脸蒙圈,取tomcat日志记录时,需要修改logstash启动服务脚本,启动用户改为root才能收集到tomcat日志。
root@logstash ~]#vim /etc/logstash/conf.d/java_tomcat.conf
input {
file {
type => "java_log"
path => "/var/log/logstash/logstash-plain.log"
start_position => "beginning"
stat_interval => "3"
}
file {
type => "tomcat_log"
path => "/usr/local/tomcat/logs/tomcat_access_log.*.log"
start_position => "beginning"
stat_interval => "3"
codec => "json"
}
}
output {
if [type] == "java_log" {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "java_log_7_10_%{+YYYY.MM.dd}"
}
}
if [type] == "tomcat_log" {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "tomcat_log_7_10_%{+YYYY.MM.dd}"
}
file {
path => "/tmp/tomcat-%{+Y-MM-dd}.log"
}
}
}
重启logstash服务后,查看els web界面:
注意:如果在收集Java日志时,日志内有多行单条目日志时,若收集上来的日志在kibana中看到的message不是多行单条目日志,需要如下书写配置文件内容,multiline插件。
input {
stdin {
codec => multiline {
pattern => "^\["
negate => "true"#true为匹配成功进行操作,false为不成功进行操作
what => "previous"#与以前的行合并,如果是下面的行合并就是"next"
}
}
}
filter { #日志过滤,如果所有的日志都过滤就写这里,如果只针对某一个过滤就写在input里面的日志输入里面。
}
output {
stdout {
codec => "rubydebug"
}
}
收集 nginx 访问日志:
部署 nginx 服务
略。。。
配置 logstash 收集 nginx 访问日志:
root@logstash ~]#vim /apps/logstash/conf.d/nginx_access.conf
input {
file {
type => "nginx_access_log"
path => "/apps/nginx/logs/nginx_access.log"
start_position => "beginning"
stat_interval => "3"
codec => "json"
}
}
output {
if [type] == "nginx_access_log" {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "logstash_nginx_access_log_%{+YYYY.MM.dd}"
}
}
}
收集 TCP/UDP 日 志
通过 logstash 的 tcp /udp 插件收集日志,通常用于在向 elasticsearch 日志补录丢失的部分日志, 可以将丢失的日志写到 一个文件,然后通过 TCP 日志收集方式直接发送logstash 然后再写入到 elasticsearch 服务器。
官方文档地址:
https://www.elastic.co/guide/en/logstash/6.8/plugins-inputs-tcp.html
logstash 配置文件先进行收集测试
root@logstash ~]#vim /apps/logstash/conf.d/tcp.conf
input {
tcp {
port => "12345"
type => "tcp_log"
mode => "server"
codec => "json" #根据输入源日志格式,按需定义是否使用json格式
}
}
output {
stdout {
codec => "rubydebug"
}
}
验证端口启动成功:

在其他服务器安装 nc 命令
NetCat简称 nc ,在网络工具中有“瑞士军刀”美誉 ,其功能实用, 是一个简单、可靠的网络工具,可通过 TCP 或 UDP 协议传输读写数据, 另外还具有很多其他功能。
root@logstash ~]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/tcp.conf
[root@zookeeper-1 ~]# yum install nc -y
[root@zookeeper-1 ~]# echo "nc test" | nc 172.20.44.12 12345
验证 logstash 是否接收到数据:
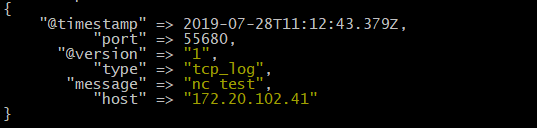
通过 nc 命令发送一个文件:
[root@zookeeper-1 ~]# nc 172.20.44.12 12345 < /var/log/messages
通过伪设备的方式发送消息:
[root@zookeeper-1 ~]# echo "伪文件" > /dev/tcp/172.20.44.12/12345
在类Unix 操作系统中, 块设备有硬盘、内存的硬件,但是还有设备节点并不一定要对应物理设备, 我们把没有这种对应关系的设备是伪设备,比如 /dev/null,/dev/zero,/dev/random 以及 /dev/tcp 和 /udp 等, Linux 操作系统使用这些伪设备提供了多种不通的功能, tcp 通信只是 dev 下面众多伪设备当中的一种设备。
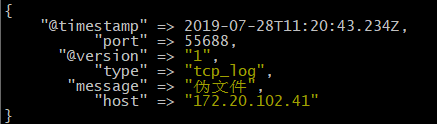
将输出改为 elasticsearch
input {
tcp {
port => "12345"
type => "tcp_log"
mode => "server"
codec => "json" #根据输入源日志格式,按需定义是否使用json格式
}
}
output {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "logstash_tcp_102.41_%{+YYYY.MM.dd}"
}
}
通过 rsyslog 收集 haproxy 日志
在 centos 6 及 之前的版本叫做 syslog , centos 7 开始叫做 rsyslog ,根据官方的介绍, rsyslog 2013 年版本可以达到每秒转发百万条日志的级别,确认系统安装的版本命令如下:
官方地址:
[root@zookeeper-1 ~]# yum list rsyslog
Installed Packages
rsyslog.x86_64 8.24.0-34.el7
使用 haproxy 日志作为收集日志的原因是为了模拟收集防火墙等外围物理设备的日志,用以分析访问日志。通过自定义haproxy日志发送到到logstash服务器监听端口,来收集要分析的日志。
Centos系统的rsyslog配置文件在/etc/rsyslog.conf,而Ubuntu系统的rsyslog配置文件在/etc/rsyslog.d/50-default.conf
haproxy安装:
# yum install haproxy
# apt-get install haproxy
Centos配置文件haproxy.cfg内容:
global
maxconn 100000
#chroot /usr/local/haproxy
#stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin
uid 99
gid 99
daemon
nbproc 1
#cpu-map 1 0
#cpu-map 2 1
#cpu-map 3 2
#cpu-map 4 3
#pidfile /usr/local/haproxy/run/haproxy.pid
log 127.0.0.1 local3 info #主要定义这行
defaults
option http-keep-alive
#option forwardfor
maxconn 100000
mode http
timeout connect 300000ms
timeout client 300000ms
timeout server 300000ms
listen stats
mode http
bind 0.0.0.0:9999
stats enable
log global
stats uri /haproxy-status
stats auth haadmin:123456
listen My_Blogs_80
bind 172.20.44.12:80
mode tcp
log global
server my_blogs 47.240.9.0 check inter 3000 fall 2 rise 5
Ubuntu配置文件haproxy.cfg内容:
global
maxconn 100000
#chroot /usr/local/haproxy
#stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin
uid 99
gid 99
daemon
nbproc 1
#cpu-map 1 0
#cpu-map 2 1
#cpu-map 3 2
#cpu-map 4 3
#pidfile /usr/local/haproxy/run/haproxy.pid
log /dev/log local0 #主要看这两行
log /dev/log local1 notice
defaults
option http-keep-alive
#option forwardfor
maxconn 100000
mode http
timeout connect 300000ms
timeout client 300000ms
timeout server 300000ms
listen stats
mode http
bind 0.0.0.0:9999
stats enable
log global
stats uri /haproxy-status
stats auth haadmin:123456
listen My_Blogs_80
bind 172.20.44.12:80
mode tcp
log global
server my_blogs 47.240.9.0 check inter 3000 fall 2 rise 5
Centos系统的rsyslog配置文件:
[root@zookeeper-1 ~]# vim /etc/rsyslog.conf
15 $ModLoad imudp #开启tcp和udp传输
16 $UDPServerRun 514
19 $ModLoad imtcp
20 $InputTCPServerRun 514
local3.* /var/log/haproxy.log #测试可以正常将日志写入本地自定义文件
local3.* @@172.20.44.12:12345 #添加一行,@@表示使用TCP协议,@表示udp协议
Ubuntu系统的rsyslog配置文件:
apt安装的haproxy默认会生成日志配置文件,名字为49-haproxy.conf
root@logstash ~]#vim /etc/rsyslog.d/49-haproxy.conf
if $programname startswith 'haproxy' then /var/log/haproxy.log
if $programname startswith 'haproxy' then @@172.20.44.12:12345
另外还需要配置文件/etc/rsyslog.conf,开启tcp和udp传输
root@logstash ~]#vim /etc/rsyslog.d/49-haproxy.conf
17 module(load="imudp")
18 input(type="imudp" port="514")
21 module(load="imtcp")
22 input(type="imtcp" port="514")
logstash 配置文件先进行收集测试
root@logstash ~]#vim /etc/logstash/conf.d/syslog.conf
input {
syslog {
port => "12345"
type => "rsys_log"
}
}
output {
stdout {
codec => "rubydebug"
}
}
测试logstash前台启动,指定配置文件syslog.conf
root@logstash ~]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf
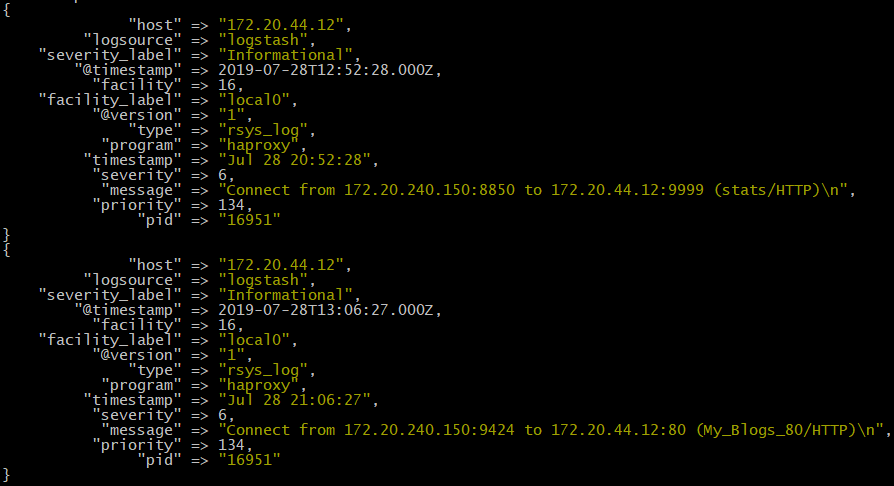
将输出改为 elasticsearch
input {
syslog {
port => "12345"
type => "rsys_log"
}
}
output {
elasticsearch {
hosts => ["192.168.7.10:9200"]
index => "logstash_rsyslog_7.12_%{+YYYY.MM.dd}"
}
}
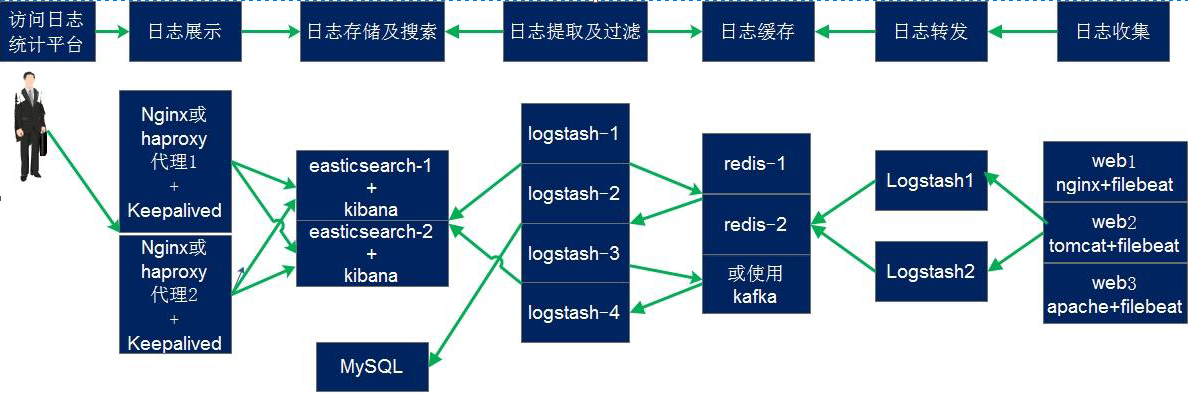
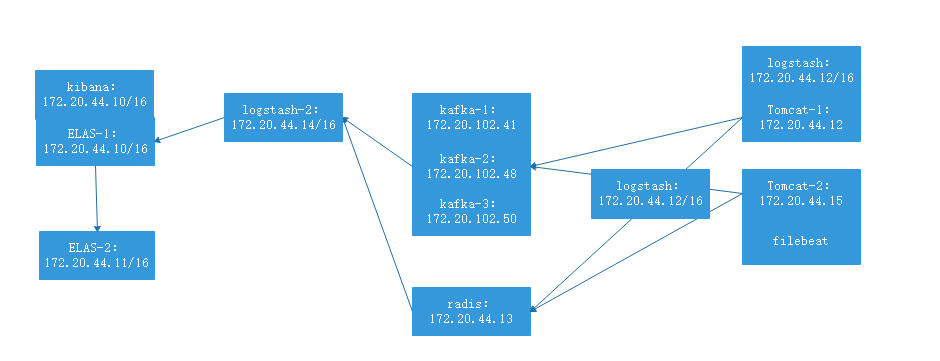
(system|nginx).log->logstash->(kafka|redis)->logstash->elasticsearch架构传输日志
透过 logstash 的 做数据处理,将日志数据存储到kafka中,再使用logstash从kafka中取出数据,直接传送给elasticsearch,kibana中添加索引,绘图。经过这么多层,为的是当服务器成百上千至上万台时,日志数据量庞大,elasticsearch服务器IO扛不住,中间同过kafka临时存储日志数据,logstach慢慢从中取,elasticsearch服务器IO也可以缓口气,至于前方的那台logstash,后续会使用filebeat代替。
kafka配置参看博文:
输出到kafa的日志格式必须定义为json格式,输入时根据源日志格式决定写不写codec => json
阿里云博客网站导出的access日志,模拟本机nginx日志,加上本机syslog日志。
root@logstash ~]#tail -n 5000 blogs_jinchenghe_top_access.log > /var/log/nginx/access.log
root@logstash ~]#setfacl -m u:logstash:r /var/log/nginx/access.log
root@logstash ~]#ll /var/log/nginx/access.log
-rw-r--r--+ 1 root root 2016975 Jul 29 14:12 /var/log/nginx/access.log
logstash 配置文件 log-kafka.conf
root@logstash ~]#vim /etc/logstash/conf.d/log-kafka.conf
input {
file {
path => "/var/log/syslog"
type => "kafka-syslog-log-7-12"
start_position => "beginning"
stat_interval => "2"
}
file {
path => "/var/log/nginx/access.log"
type => "kafka-nginx-access-log-7-12"
start_position => "beginning"
stat_interval => "2"
codec => "json"
}
}
output {
if [type] == "kafka-syslog-log-7-12" {
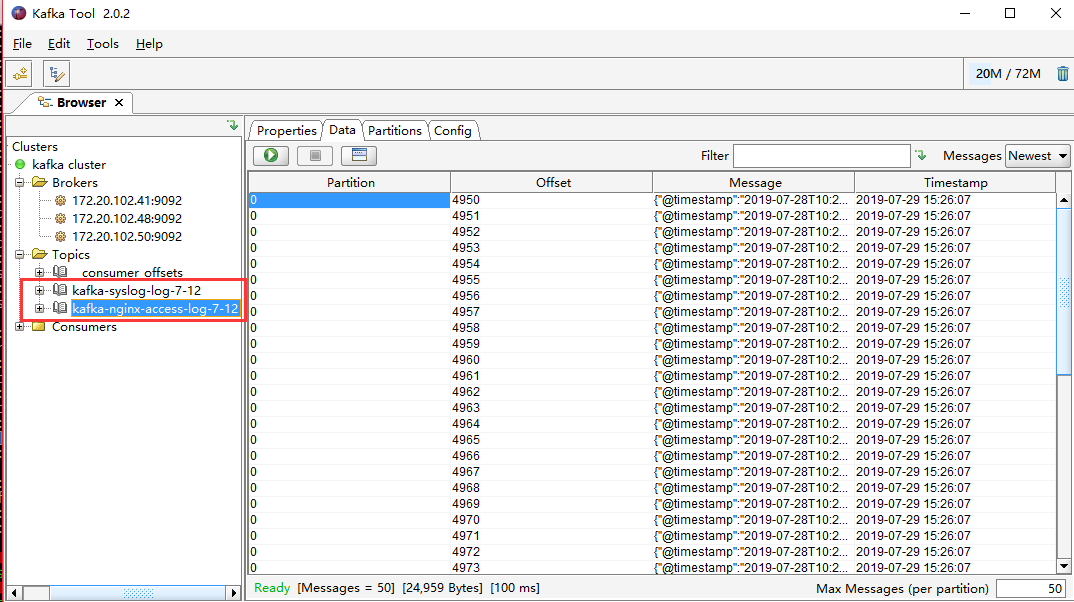
kafka {
topic_id => "kafka-syslog-log-7-12"
bootstrap_servers => "172.20.102.41:9092"
codec => "json"
}}
if [type] == "kafka-nginx-access-log-7-12" {
kafka {
topic_id => "kafka-nginx-access-log-7-12"
bootstrap_servers => "172.20.102.41:9092"
codec => "json"
}}
}
access.log日志需要重新追加数据后,kafka-nginx-access-log-7-12才会生成,为何如此暂不清楚。
root@logstash ~]#tail -n 5000 blogs_jinchenghe_top_access.log >> /var/log/nginx/access.log
重启logstash服务后,可视化工具验证数据:
接下来配置logstash-2从kafka中读取数据:
logstash-2 配置文件 log-kafka.conf
root@logstash-2 ~]#vim /etc/logstash/conf.d/log-kafka-logstash-es.conf
input {
kafka {
topics => "kafka-syslog-log-7-12"
bootstrap_servers => "172.20.102.41:9092"
codec => "json"
}
kafka {
topics => "kafka-nginx-access-log-7-12"
bootstrap_servers => "172.20.102.41:9092"
codec => "json"
}
}
output {
if [type] == "kafka-syslog-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "kafka-syslog-7-12-%{+YYYY.ww}"
}}
if [type] == "kafka-nginx-access-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "kafka-nginx-access-log-7-12-%{+YYYY.MM.dd}" #根据业务需求看是按天统计还是按周统计,周的话是ww
}}
}
需要重新追加数据后,elasticsearch中的索引才会生成
root@logstash ~]#tail -n 5000 blogs_jinchenghe_top_access.log >> /var/log/nginx/access.log
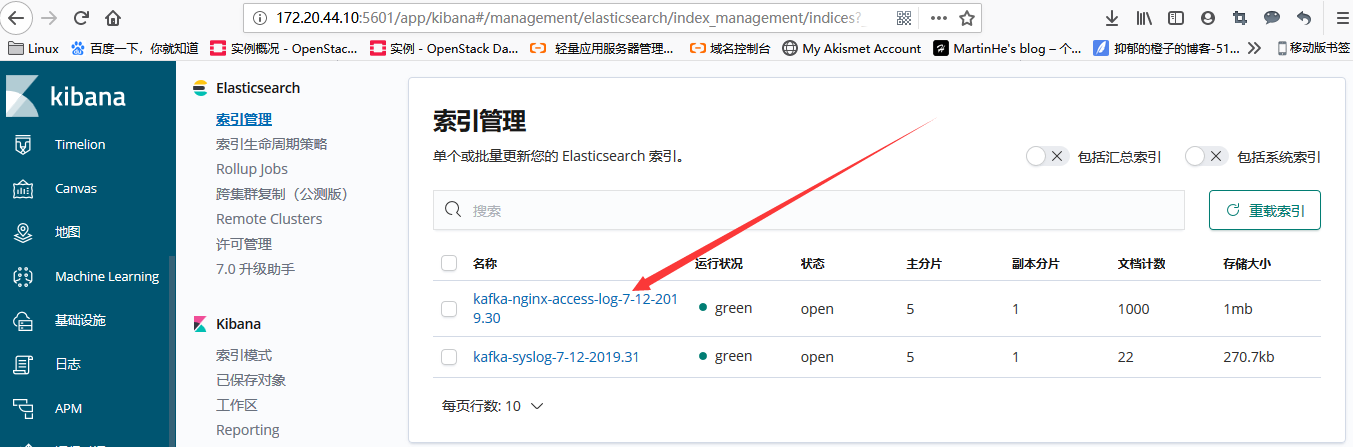
检查elasticsearch-head,或者直接从kibana索引管理中查看:
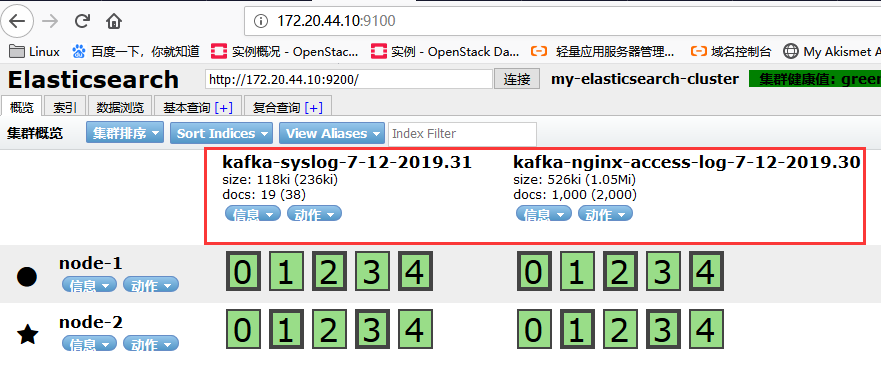
如果没数据的话,调节时间看下是否有数据命中
logstash 收集日志并写入 redis
用一台服务器部署 redis 服务, 专门用于日志缓存,适用于 web 服务器产生大量日志的场景,但要注意内存使用率,若尝试见处于高利用率可能是logstash出现问题,不能从redis中读取数据。因为 redis 服务保存了大量的数据没有被读取而占用了大量的内存空间。
中间件从kafka改为redis存储,操作如下:
[root@zookeeper-1 ~]# yum install redis
[root@zookeeper-1 ~]# vim /etc/redis.conf
61 bind 172.20.102.41
202 save 900 1 #当成中间间临时存储log时,是否自动存储,可自行设置
save "" #此为不自动触发存储到disk。
480 requirepass 123456 #设置访问密码,不然很不安全
[root@zookeeper-1 ~]# systemctl start redis
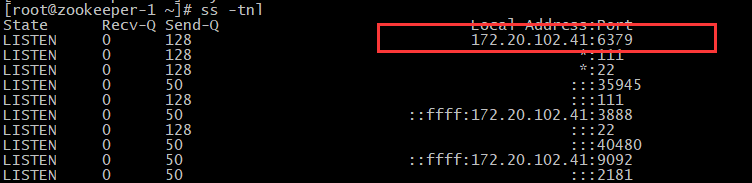
logstash 配置文件 log-redis.conf
https://www.elastic.co/guide/en/logstash/6.8/plugins-outputs-redis.html
输出到redis不需要指定codec => json。默认即为json
root@logstash ~]#vim /etc/logstash/conf.d/log-redis.conf
input {
file {
path => "/var/log/syslog"
type => "redis-syslog-log-7-12"
start_position => "beginning"
stat_interval => "2"
}
file {
path => "/var/log/nginx/access.log"
type => "redis-nginx-access-log-7-12"
start_position => "beginning"
stat_interval => "2"
codec => "json"
}
}
output {
if [type] == "redis-syslog-log-7-12" {
redis {
data_type => "list"
host => "172.20.102.41:6379"
key => "redis-syslog-log-7-12"
db => "0"
password => "123456"
}}
if [type] == "redis-nginx-access-log-7-12" {
redis {
data_type => "list"
host => "172.20.102.41:6379"
key => "redis-nginx-access-log-7-12"
db => "0"
password => "123456"
}}
}
重启logstash服务后,登录redis服务器验证数据生成情况:
[root@zookeeper-1 ~]# redis-cli -h 172.20.102.41 -p 6379
172.20.102.41:6379> AUTH 123456
172.20.102.41:6379> ping
PONG
172.20.102.41:6379> keys *
1) "redis-nginx-access-log-7-12" #此数据需要追加日志才会生成。
2) "redis-syslog-log-7-12"
logstash-2 配置文件 redis-logstash-es.conf
root@logstash-2 ~]#vim /etc/logstash/conf.d/log-redis-logstash-es.conf
input {
redis {
data_type => "list"
host => "172.20.102.41:6379"
key => "redis-syslog-log-7-12"
db => "0"
password => "123456"
codec => "json"
}
redis {
data_type => "list"
host => "172.20.102.41:6379"
key => "redis-nginx-access-log-7-12"
db => "0"
password => "123456"
codec => "json"
}
}
output {
if [type] == "redis-syslog-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "redis-syslog-7-12-%{+YYYY.ww}"
}}
if [type] == "redis-nginx-access-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "redis-nginx-access-log-7-12-%{+YYYY.MM.dd}"
}}
}
重启logstash服务后查看日志,正常为下图:
root@logstash-2 ~]#tail -f /var/log/logstash/logstash-plain.log

需要重新追加数据后,elasticsearch中的索引才会生成
检查elasticsearch-head,或者直接从kibana索引管理中查看:
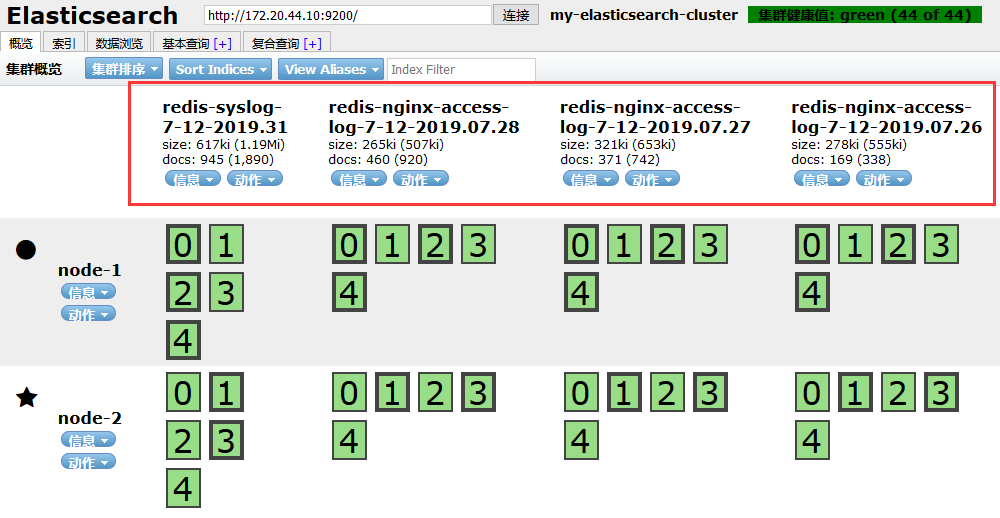
如果没数据的话,调节时间看下是否有数据命中
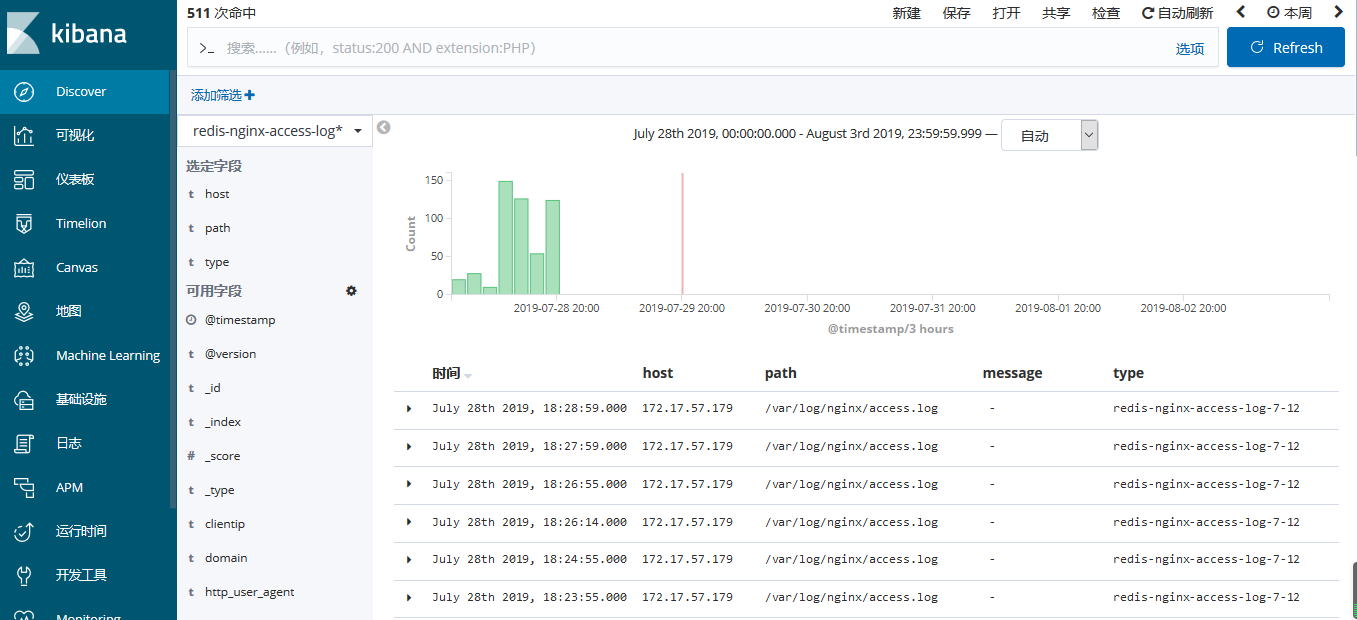
使用 filebeat 收集 日志并写入 kafka
https://www.elastic.co/cn/downloads/past-releases#filebeat
安装filebeat:
root@logstash ~]#dpkg -i filebeat-6.8.1-amd64.deb
使用 filebeat 收集 多个系统 日志:
[Mon Jul 29 20:48
root@logstash ~]#grep -v "#" /etc/filebeat/filebeat.yml | grep -v "^$"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/syslog
# exclude_lines: ['^DBG']
# include_lines: ['^ERR', '^WARN']
# exclude_files: ['.gz$']
fields:
host: "172.20.44.12"
type: "filebeat-syslog-44-12"
app: "syslog"
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
host: "172.20.44.12"
type: "filebeat-nginx-accesslog-44-12"
app: "nginxlog"
#output.file:
# path: "/tmp"
# filename: "filebeat.txt"
output.kafka:
hosts: ["172.20.102.41:9092,172.20.102.48:9092,172.20.102.50:9092"]
topic: "filebeat-systlog-accesslog-44-12"
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
启动filebeat服务后,数据会同步到kafka中,使用filebeat收集日志时,输出目的地只能有一个,不能同时拥有两个输出目的地,佛则启动服务失败,因为输出的topic只能有一个,固收集多个不同的系统日志时,要使用filed定义type类型,以便后续logstash从kafka中取得日志时,能够按日志分类提取,转存到elasticsearch中。
root@logstash ~]#systemctl restart filebeat
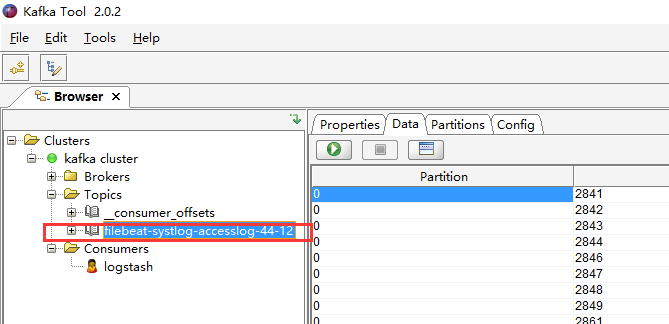
logstash-2 配置文件 filebeat-kafka-logstash-es.conf
root@logstash-2 ~]#vim /etc/logstash/conf.d/filebeat-kafka-logstash-es.conf
input {
kafka {
topics => "filebeat-systlog-accesslog-44-12"
bootstrap_servers => "172.20.102.41:9092,172.20.102.48:9092,172.20.102.50:9092"
codec => "json"
}
}
output {
if [fields][app] == "syslog" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "filebeat-syslog-44-12-%{+YYYY.ww}"
}}
if [fields][app] == "nginxlog" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "filebeat-nginx-access-log-7-12-%{+YYYY.ww}"
}}
}
重启logstash服务,观看日志启动情况,正常日志如下:

检查elasticsearch-head,或者直接从kibana索引管理中查看:
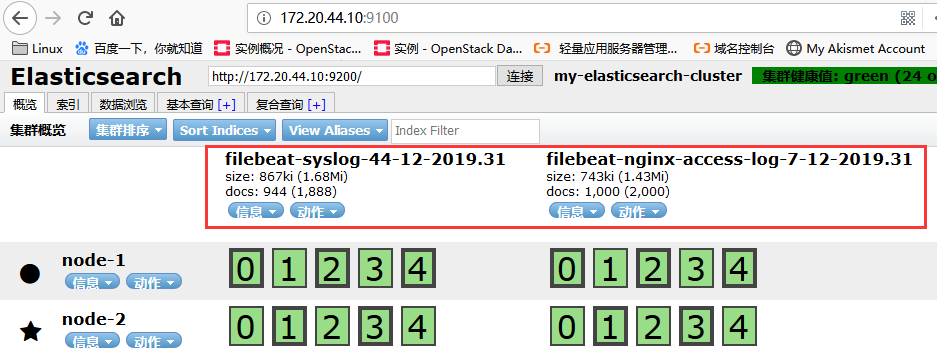
添加索引后,如果没数据的话,调节时间看下是否有数据命中
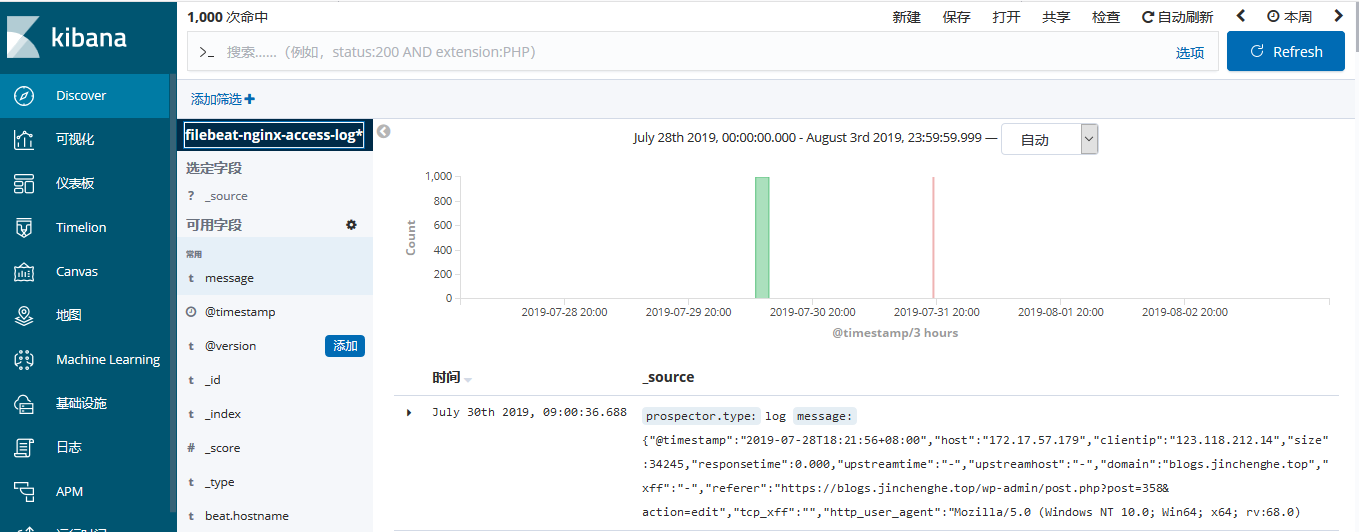
使用 filebeat 收集 日志并写入 redis
使用 filebeat 收集 多个系统 日志:
[Mon Jul 29 20:48
root@logstash ~]#grep -v "#" /etc/filebeat/filebeat.yml | grep -v "^$"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/syslog
# exclude_lines: ['^DBG']
# include_lines: ['^ERR', '^WARN']
# exclude_files: ['.gz$']
fields:
host: "172.20.44.12"
type: "filebeat-syslog-44-12"
app: "syslog"
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
host: "172.20.44.12"
type: "filebeat-nginx-accesslog-44-12"
app: "nginxlog"
#output.file:
# path: "/tmp"
# filename: "filebeat.txt"
output.redis:
hosts: ["172.20.102.41:6379"]
key: "redis-systlog-accesslog-44-12"
db: 1
timeout: 5
password: 123456
在redis服务器验证是否写入key: “redis-systlog-accesslog-44-12”

logstash-2 配置文件 filebeat-redis-logstash-es.conf
root@logstash-2 ~]#vim /etc/logstash/conf.d/filebeat-redis-logstash-es.conf
input {
redis {
data_type => "list"
host => "172.20.102.41"
port => "6379"
key => "redis-syslog-log-7-12"
db => "0"
password => "123456"
codec => "json"
}
redis {
data_type => "list"
host => "172.20.102.41"
port => "6379"
key => "redis-nginx-access-log-7-12"
db => "0"
password => "123456"
codec => "json"
}
}
output {
if [type] == "redis-syslog-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "redis-syslog-7-12-%{+YYYY.ww}"
}}
if [type] == "redis-nginx-access-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "redis-nginx-access-log-7-12-%{+YYYY.MM.dd}"
}}
}
重启logstash服务,观看日志启动情况,正常日志如下:

检查elasticsearch-head,或者直接从kibana索引管理中查看:
添加索引后,如果没数据的话,调节时间看下是否有数据命中
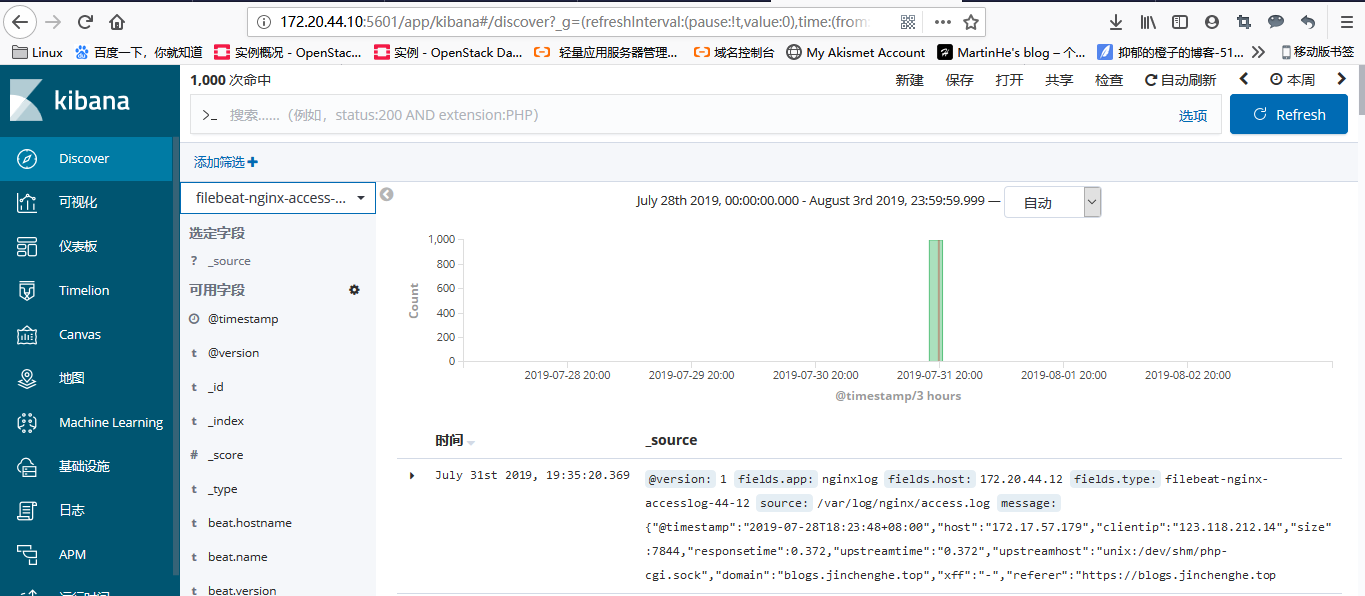
filebeat通过logstash将数据写入到redis中
https://www.elastic.co/guide/en/beats/filebeat/6.8/logstash-output.html
配置filebeat.yml文件:
output.logstash:
# The Logstash hosts
hosts: ["172.20.44.12:5044"]
enabled: true #默认即为true
worker: 1 #工作线程数
compression_level: 3 #压缩级别
# loadbalance: true #多个输出logstash时开启
logstash 配置文件 filebeat-logstash-redis.conf
https://www.elastic.co/guide/en/logstash/6.8/plugins-outputs-redis.html
https://www.elastic.co/guide/en/beats/filebeat/6.8/index.html
输出到redis不需要指定codec => json。默认即为json
root@logstash ~]#vim /etc/logstash/conf.d/filebeat-logstash-redis.conf
input {
beats {
host => "172.20.44.12"
port => "5044"
codec => "json"
}
}
output {
if [fields][app] == "syslog" {
redis {
data_type => "list"
host => "172.20.102.41:6379"
key => "redis-syslog-log-7-12"
db => "0"
password => "123456"
codec => "json"
}}
if [fields][app] == "nginxlog" {
redis {
data_type => "list"
host => "172.20.102.41:6379"
key => "redis-nginx-access-log-7-12"
db => "0"
password => "123456"
codec => "json"
}}
}
logstash-2 配置文件 filebeat-logstash-redis-logstash-es.conf
root@logstash-2 ~]#vim /etc/logstash/conf.d/filebeat-logstash-redis-logstash-es.conf
input {
redis {
data_type => "list"
host => "172.20.102.41"
port => "6379"
key => "redis-syslog-log-7-12"
db => "0"
password => "123456"
codec => "json"
}
redis {
data_type => "list"
host => "172.20.102.41"
port => "6379"
key => "redis-nginx-access-log-7-12"
db => "0"
password => "123456"
codec => "json"
}
}
output {
if [type] == "redis-syslog-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "redis-syslog-7-12-%{+YYYY.ww}"
}}
if [type] == "redis-nginx-access-log-7-12" {
elasticsearch {
hosts => ["172.20.44.10:9200"]
index => "redis-nginx-access-log-7-12-%{+YYYY.MM.dd}"
}}
}
监控 redis 数据长度:
实际环境当中, 可能会出现 reids 当中堆积了大量的数据而 logstash 由于种种原因未能及时提取日志,此时会导致 redis 服务器的内存被大量使用,甚至出现内存即将被使用完毕的情景,此时就要集合监控脚本,让zabbix去监控redis中数据长度,当达到一定数值,触发报警,通知运维人员查看redis服务或logstash服务运行状态。
脚本内容:
#!/usr/bin/env python
#coding:utf-8
#Author Zhang jie
import redis
def redis_conn():
pool=redis.ConnectionPool(host="172.20.102.41",port=6379,db=0,password=123456)
conn = redis.Redis(connection_pool=pool)
data = conn.llen('redis-systlog-accesslog-44-12')
print(data)
redis_conn()